本文转自Jerryshao Blog
Background
最近钻研于SICP (Structure and Interpretation of Computer Programs),深为lisp所抽象出的公共模式所吸引,联系一直以来所使用的Spark,想到两者对于公共模式提炼的相同之处,有感而发,记下自己的所想。
公共模式的提炼
思考程序设计中如下几种场景:
- 将一个表里的所有元素按给定因子做一次缩放
- 将一个表里的所有元素进行平方
- 将一个表里的所有元素加上一个给定值
可以看到以上三种场景可以抽象为将表内的所有元素进行某种运算得到一个新的表,本质上都是表的映射,我们可以将这种公共模式表述为一个高阶过程map,它的参数一个运算过程参数和一个表参数,返回值是将这个运算过程作用于表中每一个元素后形成的新表。可以参看场景1的例子:
(define (scale-list items factor)
(if (null? items)
nil
(cons (* (car items) factor)
(scale-list (cdr items) factor))))
对于它的抽象如下:
(define (map proc items)
(if (null? items))
nil
(cons (proc (car items))
(map proc (cdr items)))))
因此scale-list可以简化为如下:
(define (scale-list items factor)
(map (lambda (x) (* x factor))
items))
map不仅定义了一种公共模式,同时也设置了抽象屏障,将表变换过程的实现,与如何提取表中元素及组合结果的细节隔离开来,提升了抽象层次。
函数式语言提供了许多诸如map的公共模式,如reduce,foreach,filter,accumulate,利用这些公共模式,我们可以摆脱底层细节的纠缠,专注于算法的实现。
过程的公共模式拆解
同样思考以下两种场景:
- 计算出树中所有叶子节点值为奇数的平方和
- 构造出所有偶数的斐波那契数Fib(k)的一个表,其中k小于给定整数n
乍看之下上面描述的两个场景毫无共同点,无法进行抽象,实际对于复合过程的拆解会发现它们有极大的相似性,对于过程的分解可以参考下图:
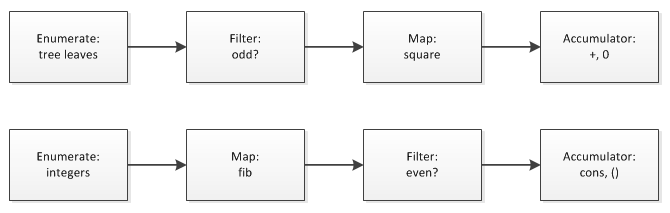
类似于信号流图,通过一些级联的步骤对过程进行子过程分解和抽象,上述两个场景都可以用一些公共模式的串联来解决。我们来看一下场景1是如何利用公共模式构造和串联的。
map模式在之前已经构造出来了,接下来我们首先是要构造filter模式:
(define (filter predicate sequence)
(cond ((null? sequence) nil)
((predicate (car sequence))
(cons (car sequence)
(filter predicate (cdr sequence))))
(else (filter predicate (cdr sequence)))))
同样我们还需要accumulate累加器对序列进行累加:
(define (accumulate op initial sequence)
(if (null? sequence)
initial
(op (car sequence)
(accumulate op initial (cdr sequence)))))
最后我们需要有一个输入序列:
(define (enumerate-tree tree)
(cond ((null? tree) nil)
((not (pair? tree)) (list tree))
(else (append (enumerate-tree (car tree))
(enumerate-tree (cdr tree))))))
将上面这些子过程串联起来我们就可以得出场景1的复合过程:
(define (sum-odd-square tree)
(accumulate +
0
(map square
(filter odd?
(enumerate-tree tree)))))
由此我们可以看到,如果语言或者库为我们提供了抽象的公共模式,我们可以利用公共模式将我们的复杂算法分解为基本的公共模式并进行串联,这样可以使算法描述更为清晰、模块化。
Spark API设计
我们知道Spark将数据集合抽象为RDD (Resilient Distributed Dataset),所有的操作过程都是基于RDD的,而RDD本质上就是一个序列,因此Spark也提供了诸如map,reduce,filter等公共模式。
Spark提供了两大类公共模式: Transformations和Actions。Transformations是将一个RDD转换为另一个RDD,是一种映射。而Actions则提供了RDD计算结果的聚合和获得。我们以word count为例简单地表述一下如何利用公共模式的复合来表述算法。
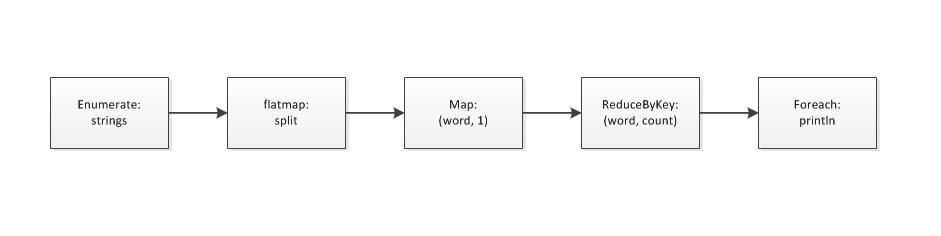
可以看到复杂的算法被分解为信号流图的表述方式,并且将不同的公共模式应用于各阶段,清晰明白地描述出了算法的构成,而程序语言的构成如下所示:
rdd.flatMap(_.split(" ")).map(r => (r, 1)).reduceByKey(_ + _).foreach(println)
Spark屏蔽了RDD的转换和实现细节,设置了抽象屏障,使我们只需关注RDD如何转换并提供行为函数,并且Spark以统一且公认的函数式公共模式提供了API,使得熟悉函数式语言的用户可以轻松地了解这些公共模式的作用。同时由于提供了众多的公共模式,因此可以将算法清晰地分解为不同模式的组合,表述更为清晰和简洁。同样是基于map-reduce的算法框架,相比于Hadoop Spark提供了更精炼的API和更高的抽象模式,使得用户可以更清晰简单地描述其算法。