本文转自Jerryshao Blog
Background
Spark Streaming has many commons compared with Spark, it abstracts DStream which based on RDD, its transformations and outputs are similar to Spark. But due to its periodically running property, some problems which may not be serious in Spark will become a big deal in Spark Streaming. This article introduce a dependency chain problem which will delay streaming job gradually and make the job crash.
Why Streaming job runs gradually slower
Problem statement
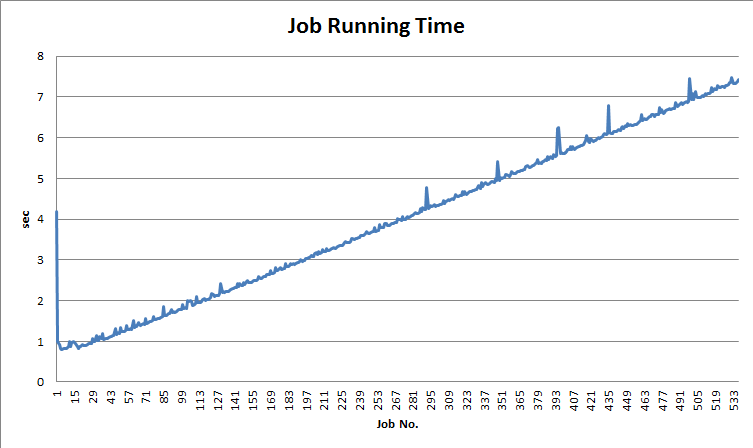
Spark Streaming job’s running time gradually slows while input data size is almost the same. You can see the job’s running time chart as below.
my job is like this:
newGenRdd = input.filer(...).map(...).join(...).countByValue()
oldRdd.zipPartition(..., newGenRdd)
Here newGenRdd will be calculated in each batch duration, oldRdd is cached in Shark’s memoryMetadataManager. Then oldRdd will be zipped with newGenRdd to get a zipped RDD, this zipped RDD will be next round’s oldRdd. So in each batch duration, job runs as above code shows.
In my zipPartition, I will filter out some records which are older than a specific time, to make sure that the total record numbers in the RDD will be stable.
So in a common sense, while the input data size is almost the same, the job’s running time of each batch duration should be stable as expected. But as above chart shows, running time gradually increase as time passes by.
Phenomenon
-
ClientDriver host’s network output grows gradually, and StandaloneExecutorBackend hosts’ network input grows gradually. You can see the below network graph of the whole cluster, in which sr412 is ClientDriver and others are StandaloneExecutorBackend
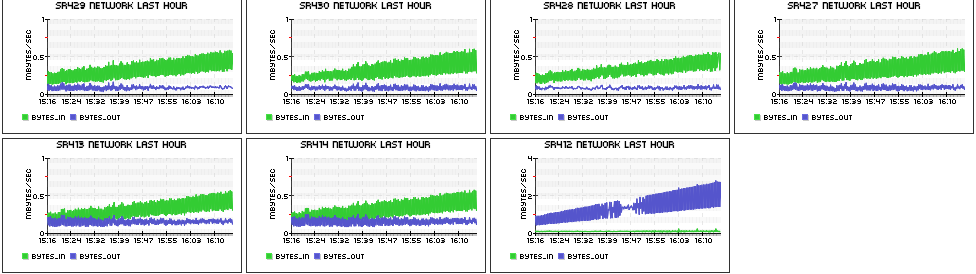
This graph shows that only ClientDriver’s network output and StandaloneExecutorBackends’ network input increases, which indicates that in each batch duration ClientDriver transmit data to all slaves, there might exists several possibilities:
- data structure created in ClientDriver transmit to slaves for closure to use.
- some dependent static data structures transmit to slaves when static functions are called on slaves’ closure.
- some control diagram transmit to slaves in Akka.
Also the growth of network traffic should be noticed, some data structures that transmited to slaves might be cumulative.
-
Serialized task size grows gradually. According to network traffic phenomenon, furtherly I dig out all the serialized task size in each job’s
zipPartitionstage, as the blow chart shows, task size gradually grows while the input data size of each batch duration is almost the same.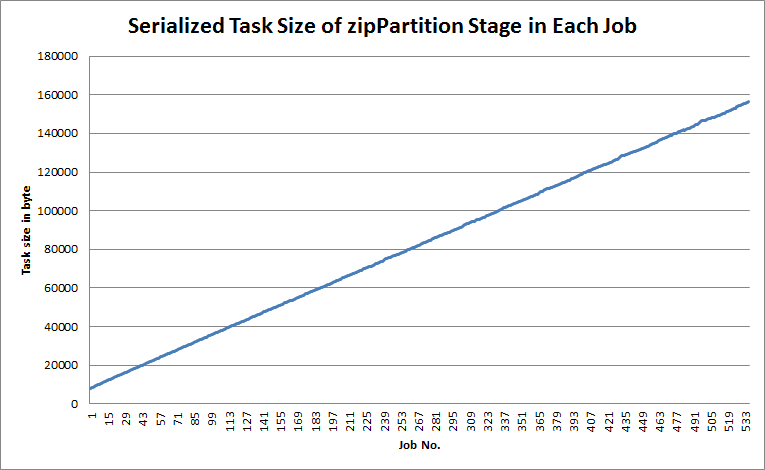
Also this
zipPartitionstage running time is increased, as blow chart shows: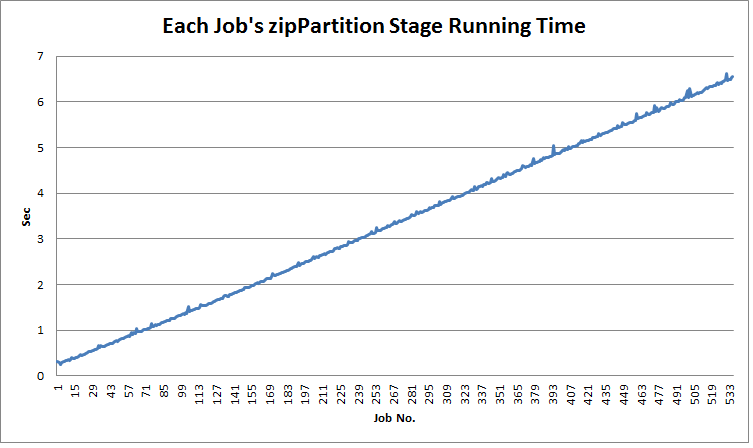
After carefully examing my implementation in
zipPartition, in which data structure is invariant in each batch duration job, so I think it might be the Spark framework introduced problem. -
I dig out all the dependencies of the
oldRddandnewGenRddrecursively, I found that as job runs periodically, dependencies ofoldRddincrease rapidly, while dependencies of thenewGenRddmaintains the same, as below chart shows.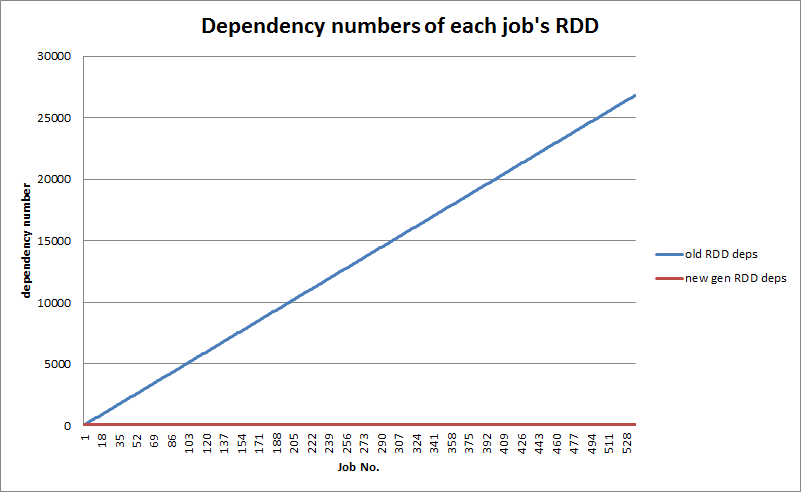
Reason
According to the above phenomena, it is obviously that the growth of dependency chain makes job being gradually slower, by investigating Spark’s code, in each batch duration, oldRdd will add newGenRdd’s dependency chain to itself, after several rounds, oldRdd’s dependency chain becomes huge, serialization and deserialization which previously is trivial now becomes a time-consuming work. Taking below code as a example:
var rdd = ...
for (i <- 0 to 100)
rdd = rdd.map(x => x)
rdd = rdd.cache
Here as you iteratively use oldRdd to do transformation, each iteration’s dependency chain will be added to recently used rdd, lastly this rdd will have a long dependency chain including all the iterative’s dependency. Also thls transformation will run gradually slower.
So as included, the growth of dependencies makes serialization and deserialization of each task be a main burden when job runs. Also this reason can explain why task deserialization will meet stack overflow exception even job is not so complicated.
I also tested without oldRdd combined, each time newGenRdd will be put in Shark’s memoryMetadataManager but without zip with oldRdd, now the job running time becomes stable.
So I think for all the iterative job which will use previously calculated RDD will meet this problem. This problem will sometimes be hidden as GC problem or shuffle problem. For small iteratives this is not a big deal, but if you want to do some machine learning works that will iterate jobs for many times, this should be a problem.
This issue is also stated in Spark User Group:
Is there some way to break down the RDD dependency chain?
One way to break down this RDD dependency chain is to write RDD to file and read it back to memory, this will clean all the dependencies of this RDD. Maybe a way to clean dependencies might also be a solution, but it is hard to implment.