目录
Background
本文讲在网易工作将近一年来关于Spark Shuffle方面所做的三点优化。
前言
Spark是目前主流的大数据计算引擎,而Shuffle操作是Spark计算中的的核心操作,也往往是瓶颈所在。首先简单介绍下Shuffle操作。如下图所示.
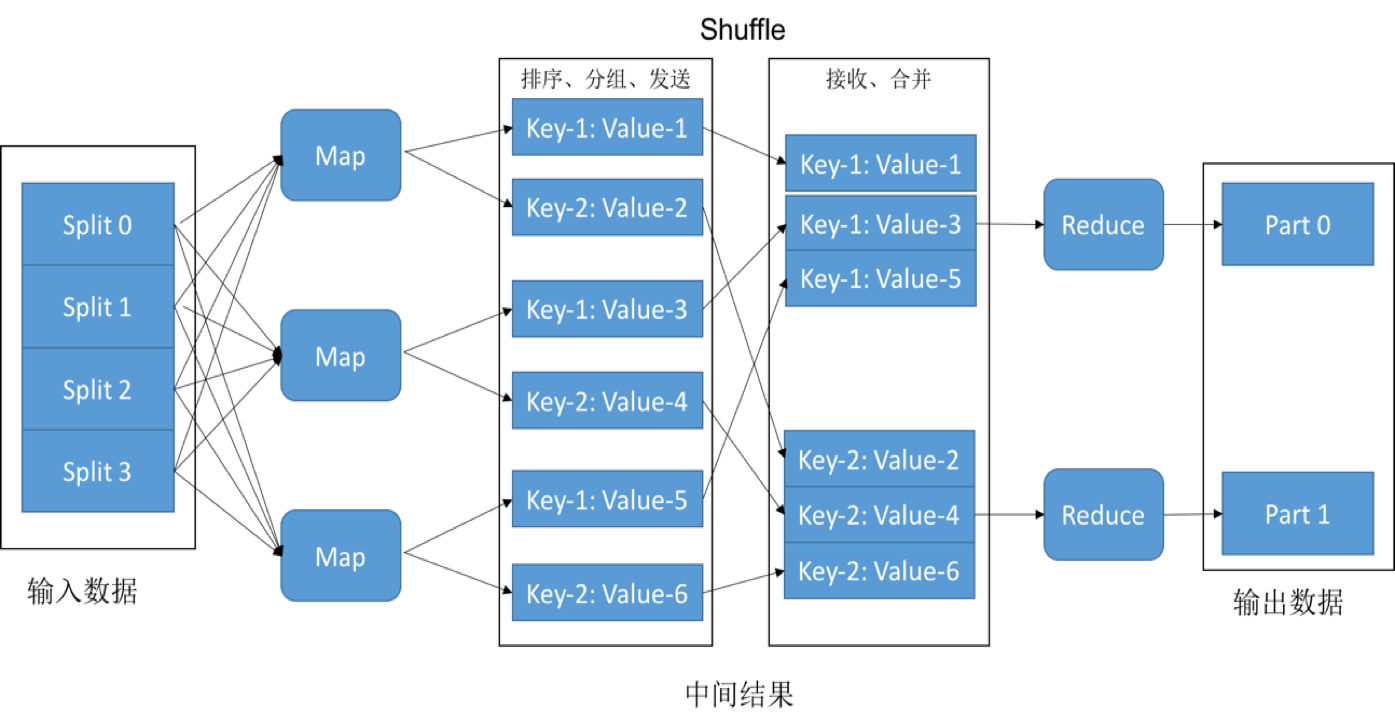
map端负责对数据进行重新分区(Shuffle Write),可能有排序操作,而reduce端拉取数据各个mapper对应分区的数据(Shuffle Read),然后对这些数据进行计算。Shuffle过程中伴随着大量的数据传输。在大数据生产环境中,数据规模日益增长,数据量大了什么事情都有可能发生,可能会产生各种各样的问题,而大多数问题都与shuffle有关。由于Shuffle数据传输是由Shuffle read端fetch数据,因此本文使用fetch代表传输。
本文主要讲关于Spark Shuffle传输方面的三点优化。
- 可以传输 Can Fetch.
- 高效率传输 Fetch Efficiently.
- 可靠的传输 Reliable Fetch.
Can Fetch
通常来说,Spark作为一个主流的大数据计算引擎,是可以传输大多数的Shuffle数据的。但是在大数据生产中,往往面临一些极端的shuffle情况。下面的案例是来自网易云音乐的用户。
描述
一天用户告诉我他有一个任务在Shuffle Read阶段出错,每天都要重试,有时候重试一次,有时候重试几次可以成功。任务报错如下:
WARN [shuffle-client-6-2:TransportChannelHandler@78] - Exception in connection from hostName/hostIp:7337
java.lang.IllegalArgumentException: Too large frame: 2991947178
at org.spark_project.guava.base.Preconditions.checkArgument(Preconditions.java:119)
at org.apache.spark.network.util.TransportFrameDecoder.decodeNext(TransportFrameDecoder.java:133)
at org.apache.spark.network.util.TransportFrameDecoder.channelRead(TransportFrameDecoder.java:81)
at io.netty.channel.AbstractChannelHandlerContext.invokeChannelRead(AbstractChannelHandlerContext.java:362)
通过观察日志,我发现,是用户的一个MapTask发生了严重的数据倾斜,导致了这个MapTask写文件时有一个partition的数据量超过了2GB。而spark 使用netty进行数据传输,单个chunk有一个严格的2GB限制,因此这必然导致了在一次拉取单个partition shuffle 数据大于2GB时的失败。
那么用户又为什么任务可以重试成功呢?通过观察spark 日志页面.

可以发现此task在shuffle read端读取数据量为2.5GB,而从远端节点读取的数据量仅为42.5MB,原来是因为在该task失败之后,会进行重试,task可能重新调度到该oversize的partition所在的节点,这样数据就在本地,不用从网络中拉取,自然也不会触发到2GB的限制。
看来用户还是比较幸运的,重试之后可以刚好调度在数据所在节点执行task。那么如果有两个partition的数据都发生了严重的倾斜,而且这两个partition不在同一个节点之上,那样无论任务怎么重新调度,都必然至少有一个partition无法fetch,这必然造成了task的失败,进一步造成application的失败。
继续分析这个问题,spark有一个参数spark.maxRemoteBlockSizeFetchToMem,代表着可以从远端拉取数据放入内存的最大size。如果这一批要拉取的数据大小之和小于这个值,那么spark 使用fetch chunk的方式,都是一次拉取一整块的partition数据,然后放在内存里。如果一批要拉取数据大小之和大于这个size,就会采用fetchStream的方式,将这些partition数据流式拉取到本地保存为本地文件。
在spark2.4之前这个参数默认都是Long.MaxValue,这个值是超级大的,所以可以认为spark2.4之前如果你没有对这个参数进行额外设置,比如设置为2G,1500m,就可以说你的所有partition拉取都是一次进行。
而spark2.4之后,对该参数的默认值更改为Integet.MaxValue-512,也就是说,这样的参数就不会触发到一次性拉取一个大于2GB的数据了。
优化方案
问题已经分析的很明确。该问题的解决方案可以分为三种。
- 通过设置
spark.maxRemoteBlockSizeFetchToMem为小于2GB,来避免发生这个问题,这是最简单的 - 或者是用户解决数据倾斜的问题
- 从平台侧解决这个问题。
讲一下从平台侧对这个问题的解决,Spark作为一个大数据计算引擎,一个partition有超过2GB的数据并不过分,而作为一个大数据平台开发,自然要积极从平台侧出发。
而虽然能够通过配置spark.maxRemoteBlockSizeFetchToMem小于2GB来避免这个问题的发生,但是这也造成了即使我们在资源充足的情况下,也不能将这个参数设为一个大于2GB的值,而这也就造成了有时候即使我们内存资源充足,当我们一批fetch数据大于2GB时也要将这些数据进行落盘,新增了一些I/O开销。因此,我们能不能突破这个spark.maxRemoteBlockSizeFetchToMem不能设置大于2GB的限制,在任何设置下都能成功的取到数据呢?
其实一开始看到用户的任务可以通过重新调度到partition所在节点上解决之后,曾经想过使用调度优化来解决,但是前面也提过,如果有两个partition oversize,那么这个任务必定失败。
因此想到了对比较大的partition进行划分,每次拉取一部分数据,这样就不会触发到netty的2GB限制。
首先描述一下目前Spark 在没有达到spark.maxRemoteBlockSizeFetchToMem限制时拉取数据的过程。
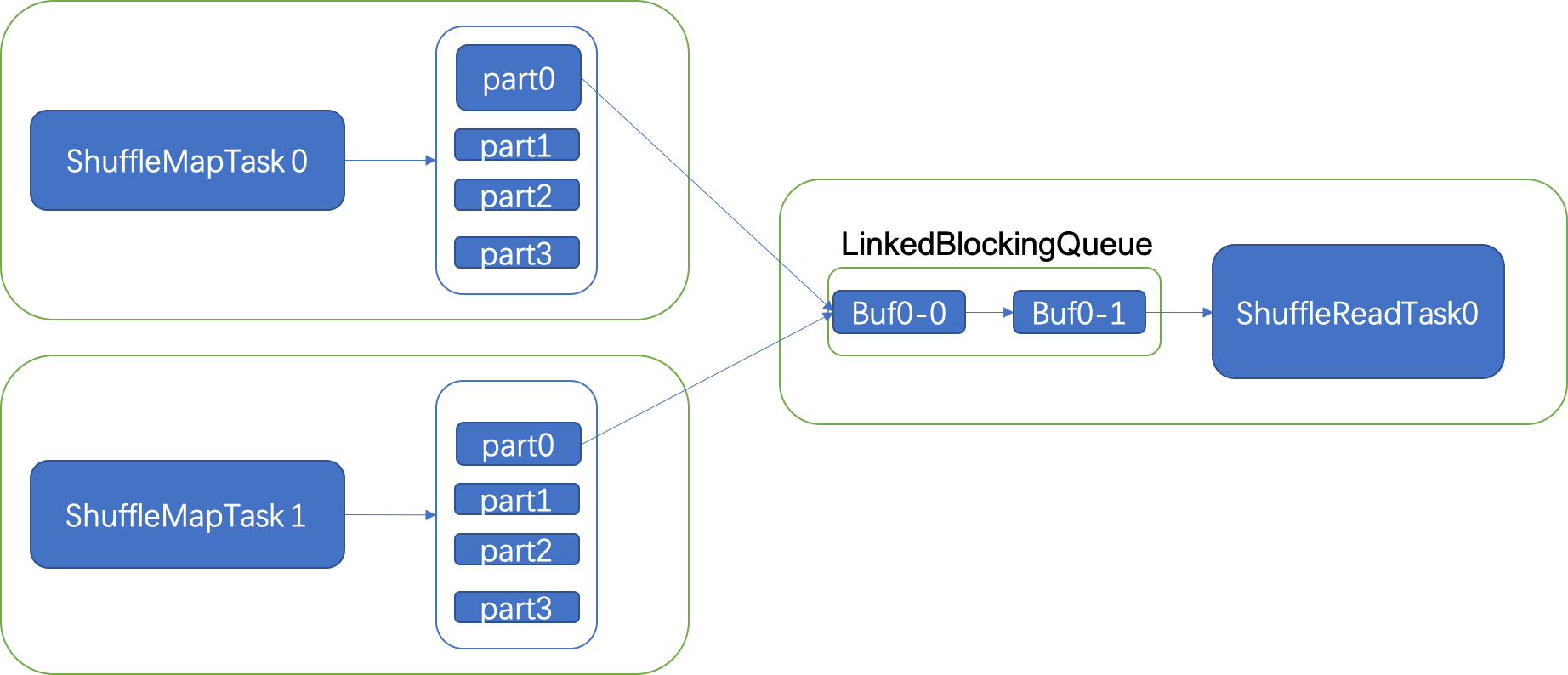
如上图所示,可以看到,shuffle read端将每个partition对应的数据,作为一个ManagedBuffer拉取过来,存放在一个阻塞队列中,之后task会依次去取这些数据进行计算。这就是目前shuffle fetch的不足之处,不管对应的partition有多大,只要这批拉取数据量小于spark.maxRemoteBlockSizeFetchToMem都一次性去取过来。
我们针对此方案作出了优化:现简单描述如下:
-
设置Shuffle一次可以fetch的阈值
SHUFFLE_FETCH_THRESHOLD为2GB -
设置一个参数
spark.shuffle.fetch.split来控制是否使用本方案拉取数据 -
在创建mapStatus阶段,计算每个partition需要被fetch的次数
size/SHUFFLE_FETCH_THRESHOLD保存为map.为了节省内存空间只保存次数1次以上的, 从map中获取不到则为1次。 -
定义一种新的BlockId 为
ShuffleBlockSegmentId,用来让shuffle 服务端来识别出来我们要使用什么样的方案获取数据。 -
在shuffle client端,根据
spark.shuffle.fetch.split参数来创建我们要发送到shuffle 服务端的BlockID类型,如果是多次拉取,则创建ShuffleBlockSegmentId,否则还是之前的ShuffleBlockId. -
对于一个ShuffleBlockID对应的partition数据,使用一个buf的Sequence来保存,而不是原来的只用一个buf来保存。
-
由于我们现在分多次拉取一个partition的数据,因此需要这个partition数据完全拉取结束之后才能进入原来的LinkedBlockingQueue, 因此我们使用一个PriorityBlockingQueue来存放一个partition对应的多块数据,而且优先级阻塞队列还提供了排序功能,我们可以保证一个partition的数据是按序排放。当该ShuffleBlockId对应的所有数据都拉取过来之后,将放在优先级队列中的buf出队,然后放入LinkedBlockingQueue中,供task用于取数据计算。
-
在shuffle服务端,通过识别我们发送的blockId类型来决定如何取数据,如果是
ShuffleBlockSegmentId,则取一块数据,否则,取全部数据。新方案拉取过程如下图所示:
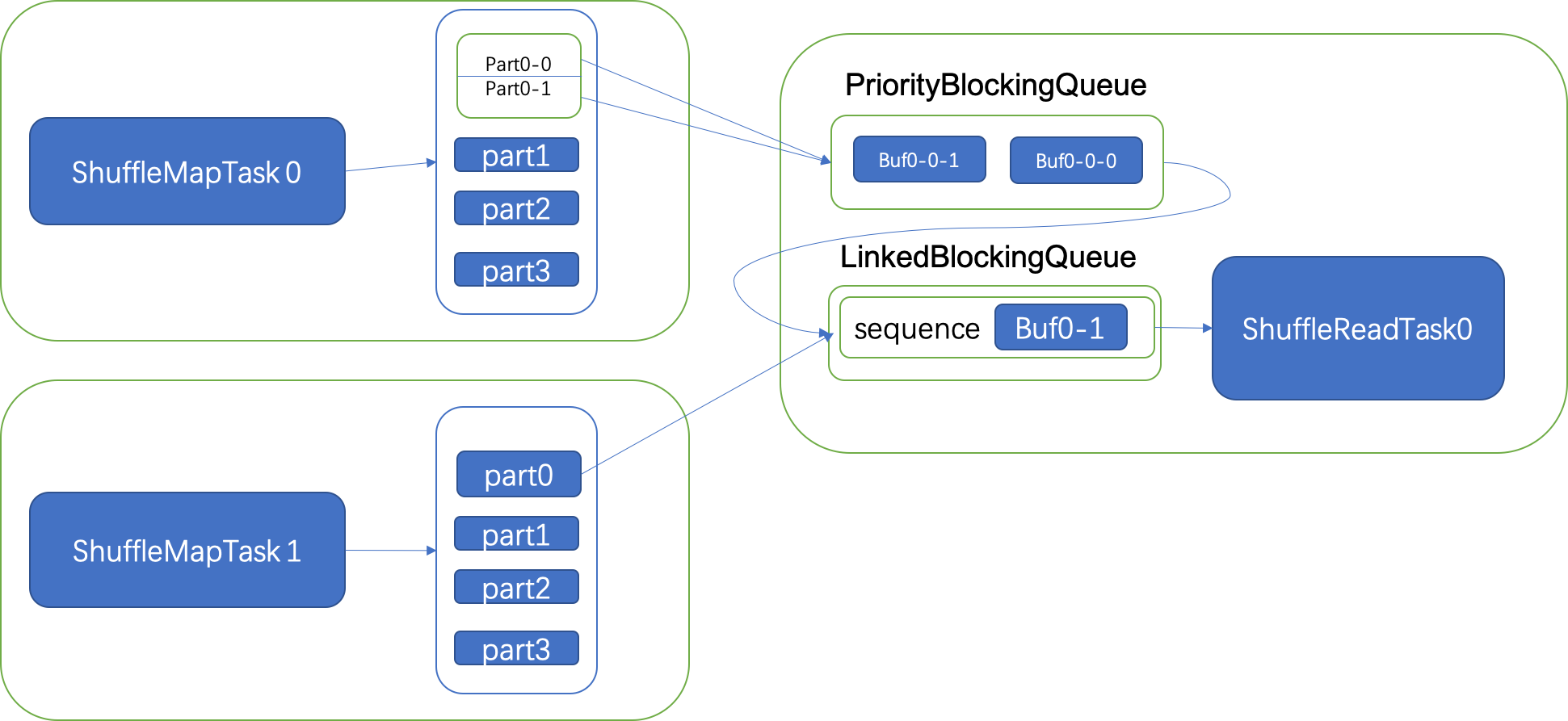
通过此方案,我们就可以突破
spark.maxRemoteBlockSizeFetchToMem2GB和单partition数据量大于2GB的限制,为所欲为。
相关链接
另外由于近期PR-SPARK-27665的合入,我对新的shuffle fetch消息类型,也进行了适配。
对应Jira SPARK-27876
对应PR SPARK-27876
Fetch Efficiently
除了上面的能够传输,我们还要高效率的传输。下面的案例来自考拉的一个用户。
描述
考拉的一个用户告诉我,他近期的部分任务大量延迟,虽然没有task失败,但是运行时间比平时多了很多。
还是看日志,通过观察日志,发现用户的任务中有大量的shuffle-client拉取数据超时,然后重试的操作。
2019-04-26 12:18:49,848 [25708] - INFO [Executor task launch worker for task 1689:Logging$class@54] - Started reading broadcast variable 5
2019-04-26 12:18:49,906 [25766] - INFO [Executor task launch worker for task 1689:TransportClientFactory@254] - Successfully created connection to hadoop3977.jd.163.org/hostIp:38939 after 1 ms (0 ms spent in bootstraps)
2019-04-26 12:18:50,291 [26151] - WARN [shuffle-client-4-1:TransportChannelHandler@78] - Exception in connection from hadoop3977.jd.163.org/hostIp:38939
java.io.IOException: Connection reset by peer
at sun.nio.ch.FileDispatcherImpl.read0(Native Method)
at sun.nio.ch.SocketDispatcher.read(SocketDispatcher.java:39)
at sun.nio.ch.IOUtil.readIntoNativeBuffer(IOUtil.java:223)
at sun.nio.ch.IOUtil.read(IOUtil.java:192)
重试操作是spark shuffle 阶段的一个优化,这可以避免由于网络或者节点暂时繁忙而导致拉取数据失败,而是可以多重试几次,保证数据拉取的健壮性,避免贸然的失败。可以使用 spark.shuffle.io.maxRetries 和spark.shuffle.io.retryWait来配置最大重试次数与重试时间间隔。
日志中是说,这个shuffle-client一直连接超时,然后不断重试,直到将重试次数用尽。如果我们配置的最大重试次数为15次,重试间隔为20s的话,这样一个task不断重试下来就要推迟五分钟,如果很多的task推迟,后果很严重。
首先介绍一下shuffle client, spark中有两种shuffle client。一种是blockTransferService,用于拉取由spark自身管理的数据;另外一种是 ExternalShuffleClient,是用于拉取外部shuffle 服务的数据。常用的ExternalShuffleService是yarn上的shuffle service,它独立运行在yarn集群上的每个nodemanager之上,用于管理spark在运行阶段生成的shuffle数据,因此spark上的executor就不用自己管理自己的shuffle 数据。这也就为executor的动态回收提供了可能,因此如果没有额外的shuffle Service帮助这些executor管理他们的shuffle数据, 如果一个executor回收掉了,那么这些shuffle数据也就不可见。因此在spark中,如果要使用executor动态回收,必须要有对应的外部shuffle Service。
前面说了有两种shuffle client,blockTransferService是用于拉取由spark自身管理的数据,现在有了ExternalShuffleService用于管理shuffle 数据,那么blockTransferService还有什么作用呢?那就是拉取Broadcast数据。
上面的日志也是说重试时发生在reading broadcast variable阶段。
通过对日志进行详细的分析,问题如下:
- executorA 要拉取Broadcast变量,向executorB建立连接,成功。
- 建立连接成功之后,由于executorB到达最大空闲时间,被动态回收。
- executorA取数据时候发生超时,然后重试,重试必然会失败。
- 不断重试,直到重试此处用尽,之后executorA向Driver索要数据,成功。
整个流程下来,这个task并没有失败,但是花费了大量的时间在不断的重试之上。
优化方案
通过对问题深入的分析,发现问题出现在RetryingBlockFetcher的重试逻辑。
其重试逻辑如下:
- 如果当前异常为IOException(网络也是一种IO)。
- 并且此时还有重试次数未用尽,那就继续重试。
但是当初设计这个重试逻辑的人可能忽略了ExecutorDynamicAllocation,因为executor很容易被回收,当fetch数据时相关的节点已经死掉时,也会抛出IO异常,因此这会触发RetryingBlockFetcher的重试逻辑,但是这样的重试显然是毫无意义的,因此你永远不可能向一个已经死掉的executor索要数据。
因此,我对此重试进行了优化。
- 设置一种新的消息类型,
IsExecutorAlive.在BlockTransferService捕获到IOException时,发往driver。 - driver根据消息中的executorID来查找自己维护的一个以executorId为key的map,时间复杂度为o(1),如果此executorId在map中则代表存活,否则,该Executor已经被回收.
- 回复executorId对应的Executor状态给索要信息的executor。
- 根据返回结果,如果该executor依然存活,则重试,否则,抛出ExecutorDeadException,重试结束。
核心代码如下:
try {
new OneForOneBlockFetcher(client, appId, execId, blockIds, listener,
transportConf, tempFileManager).start()
} catch {
case e: IOException =>
Try {
driverEndPointRef.askSync[Boolean](IsExecutorAlive(execId))
} match {
case Success(v) if v == false =>
throw new ExecutorDeadException(s"The relative remote executor(Id: $execId)," +
" which maintains the block data to fetch is dead.")
case _ => throw e
}
}
通过对shuffle-client(blockTransferService)重试逻辑的优化,我们可以避免无意义的重试,高效率的进行数据传输,提高应用性能。
相关链接
该PR已经合入Spark master分支.
对应Jira SPARK-27637
对应PR SPARK-27637
Reliable Fetch
前面提到了Can fetch, fetch efficiently,保证了可以传输任何数据,可以高效率的传输数据,数据传输的可靠性也是必要的,最后一部分聊一聊我们针对spark shuffle数据传输的可靠性做的优化。
描述
前面已经讲过spark shuffle过程中有大量的网络传输,也讲过shuffle read端fetch数据的过程。既然有大量的网络传输,那么就可能会有数据传输出错,所以对数据的校验是必不可少的。
shuffle read端在拉取到数据之后,首先会进行数据校验,然后进行后续的计算,如果该校验没有校验出数据的问题,而在后续的计算过程中发现该数据已经损坏,那么就会导致该task失败。
会报以下类似异常.
18/11/13 08:10:08 INFO client.TransportClientFactory: Successfully created connection to hadoop2997.lt.163.org/hostIp:7337 after 0 ms (0 ms spent in bootstraps) 18/11/13 08:10:08 ERROR util.Utils: Aborting task java.io.IOException: FAILED_TO_UNCOMPRESS(5) at org.xerial.snappy.SnappyNative.throw_error(SnappyNative.java:98) at org.xerial.snappy.SnappyNative.rawUncompress(Native Method) at org.xerial.snappy.Snappy.rawUncompress(Snappy.java:474) at
这个异常是在后续计算过程中报的,说明目前的spark shuffle 数据校验机制存在问题。
首先描述一下在一个相关PR SPARK-26089合入之前存在的问题.
- 只校验使用数据压缩格式(例如snappy,lz4)的数据,而非压缩的数据不进行校验。
- 只能校验小于
maxBytesInFlight/3(默认maxBytesInflight为48M)的数据,大小有局限 - 采用创建的一个outputStream,然后将InputStream传入,然后再基于这个outputStream创建inputStream的方式来校验,会浪费内存
相关PR SPARK-26089合入解决了部分问题:
- 针对较大的数据,也可以校验,但是只校验开头的一小部分,后面的数据不进行校验,如果后面的数据出错依然会造成task失败
- 采用新的校验方法取代之前的流拷贝校验方法,内存浪费情况得到改善。
但是依然存在以下问题:
- 无法校验未使用数据压缩格式的数据,谁又能确定不使用压缩格式就不出错呢?
- 针对较大的数据,只校验起始部分,依然存在后续数据corrupt的风险
优化方案
我们通过针对线上的流数据corrupt异常分析以及对目前spark的校验机制分析,提出了一个相较完善的Spark shuffle 数据校验机制。
首先,我们需要选择一种数据通信校验码。通过对比了md5, sha系列,以及crc32等几种校验码,我们选取了crc32,因此crc它快速而又简单,完全满足生产需求,hadoop也是使用crc来作为数据校验码.
我们的方案简单描述如下:
- shuffle map阶段针对每个partition计算其crc值,将这些crc值存储
- 在shuffle read阶段拉取数据时,将数据对应的crc值与数据一起发送
- shuffle read端针对拉取的数据重新计算crc值,与原有的crc值进行比对,比对相同,则代表数据传输没有问题,反之,有问题。
下面是具体实现。
Shuffle Write Phase
首先简单介绍一下shuffle write。shuffle writer分为三种,BypassMergeSortShuffleWriter, SortShuffleWriter和UnsafeShuffleWriter. BypassShuffleWriter最后写的shuffle block组织方式与后两种不同,后两种shuffle writer的shuffle block文件组织方式是相同的。
如下图所示.
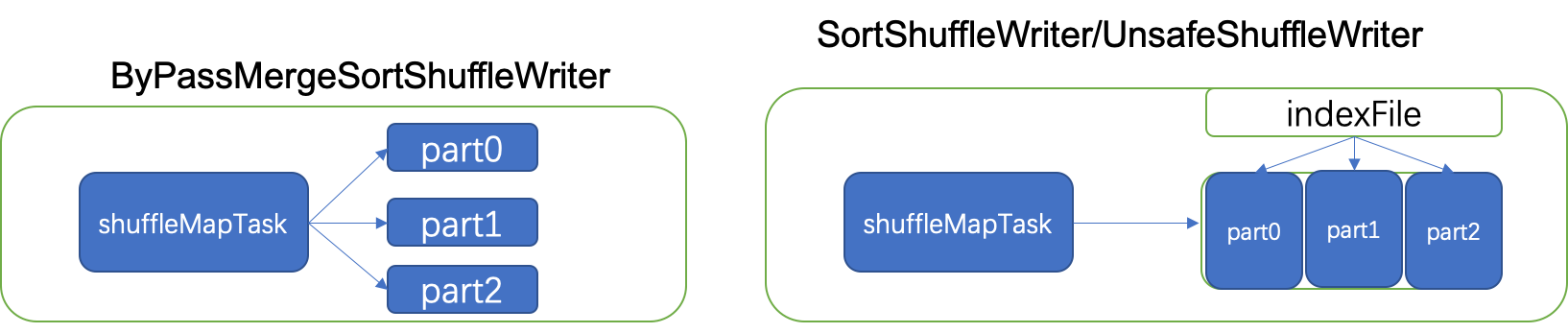
由图可见,如果一个shuffle过程有m个mapper, n个reducer。那么BypassShuffleWriter会创建 m*n个shuffle文件,如果m和n都比较大,比如m=n=5000,那么就会创建2500万个文件,这很可怕,所以BypassShuffleWriter默认只会在reducer个数少于200的时候使用,可以通过spark.shuffle.sort.bypassMergeThreshold配置这个参数。
而SortShuffleWriter和UnsafeShuffleWriter的组织shuffle文件的方法是一样的,这是针对BypassShuffleWriter的改进。由图可见,这两种shuffleWriter只会针对一个mapTask创建一个shuffle文件,建立一个索引文件记录每个划分之后的partition数据在这个文件中的偏移量(BypassShuffleWriter也有这样的索引文件)。这样每个mapTask只创建了两个文件,一个数据文件,一个索引文件,大大减小了文件的数量,减小了系统的压力。
而我们会在shuffle阶段数据处理完成之后,根据索引文件中记录的每个partition的偏移量计算每个partition的crc值,这个计算过程是很快的,crc是一个高效的校验码,而且通常(后两种ShuffleWriter是通常使用的)我们只需打开一个输入流,从头计算到尾,这是一个很高效的过程。
计算完成之后,我们将这些计算的crc值也存到到前面提到的shuffle索引文件,组织方式如下图。
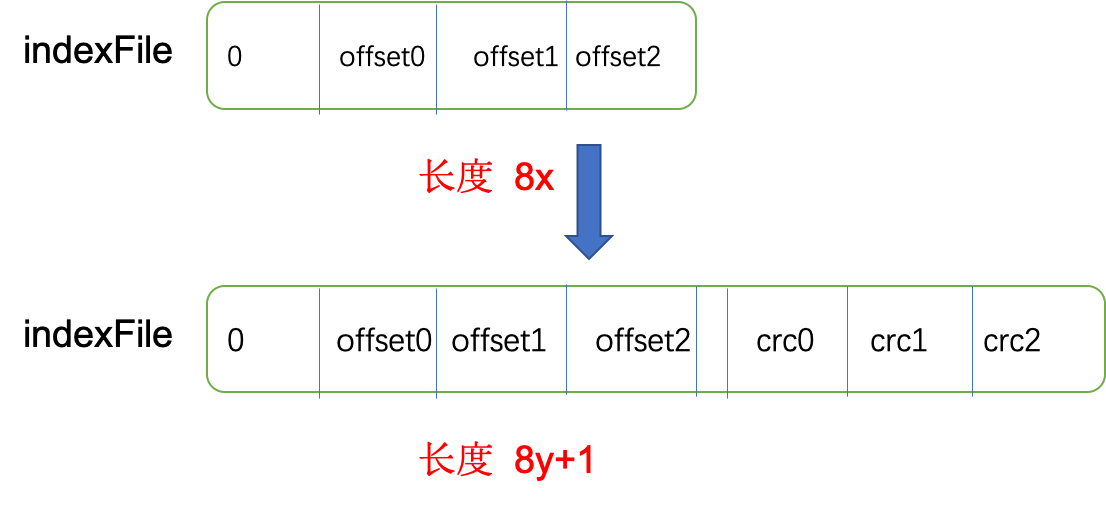
原有的index文件保存的是每个分区的偏移量,都是long类型,每个偏移量占用8字节,因此其长度是8的倍数。
如果我们在原有的index文件后面添加计算的crc值,我们会加一个标志位,占用一个字节,之后的每个crc32值都是一个long类型,占用8字节,这样新的index文件长度就是(8y+1),永远不可能是8的倍数,而原有的shuffle index文件长度一定是8的倍数,这样ExternalSHuffleService也能都轻易识别出我们是否使用了crc校验,和老版本的spark进行兼容。
Shuffle Read Phase
前面已经提到过shuffle fetch数据的过程,只不过这里会在读数据时候,将map阶段计算的对应partition部分的crc值也一起拉取过来,然后与拉取过来的数据重新计算得到的crc值进行对比。
前面也提到过,如果一批拉取的数据的量小于spark.maxRemoteBlockSizeFetchToMem是会将数据全部放在内存中的,只有超过这个数量才会将远端的数据先落磁盘然后之后再读取,因此保存在磁盘中的数据,包括本地的shuffle block文件与远端拉取落磁盘的文件。
针对远端拉取过来放在内存中的数据,由于其本身就在内存,因此对其计算crc值是十分迅速的,而且内存中inputStream支持reset操作,我们在计算crc之后,进行一下reset操作,就可以继续将这个inputStream用于后续的task计算。
而针对在磁盘中数据,我们对其计算crc值,前面提过了crc是一个高效的校验码,这个过程也是很快的, 在将从磁盘数据得到的inputStream计算完之后,只需要将该inputStream关掉,然后重新从这个磁盘文件创建一个新的inputStream用于后续的task计算。
而在整个map阶段和reduce阶段,计算crc值只需要一个几十kb的缓冲区。
在shuffle read端计算完crc值之后,可以跟原来的crc值对比,如果对比一致,则代表该数据没有问题,否则就要进行一系列的处理逻辑,此处不再赘述。
这样,我们的shuffle校验机制就针对目前的spark shuffle校验机制进行了完善,可以校验非压缩的数据,可以校验任意大小的数据,cover所有场景。
性能测试
我们使用tpcds测试工具,针对1t和10t的数据进行了该校验算法的性能测试,其测试结果表明该算法不会对spark本身的执行性能造成影响,且在10T测试数据下, 由于最老版本的shuffle校验采用流拷贝,可能开销比较重,我们的shuffle校验机制,对比其有轻微的性能提升。针对最近合入的相关PR SPARK-26089,我们还没有进行性能测试对比,但是相信,我们的shuffle校验机制对比其不会有性能下降。
相关链接
对应Jira SPARK-27562
对应PR SPARK-27562