目录
Background
从最简单的spark应用WordCount入手,分析rdd链,分析job如何提交,task如何提交,从全局了解spark应用的执行流程。
Word Count
word count是spark 最基本的小程序,主要功能就是统计一个文件里面各个单词出现的个数。代码很简洁,如下。
import org.apache.spark.{SparkConf, SparkContext}
object SparkWC {
def main(args: Array[String]) {
val sparkConf = new SparkConf()
val sparkContext = new SparkContext(sparkConf)
sparkContext.textFile(args(0))
.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.saveAsTextFile(args(1))
}
}
理论剖析
里面的RDD链,用他们的操作表示,就是textFile->flatMap->map->reduceBykey->saveAsTextFile.
spark里面有两种操作,action 和transformation,其中action会触发提交job的操作,transformation不会触发job,只是进行rdd的转换。而不同transformation操作的rdd链两端的依赖关系也不同,spark中的rdd依赖有两种,分别是narrow dependency 和 wide dependency ,这两种依赖如下图所示。
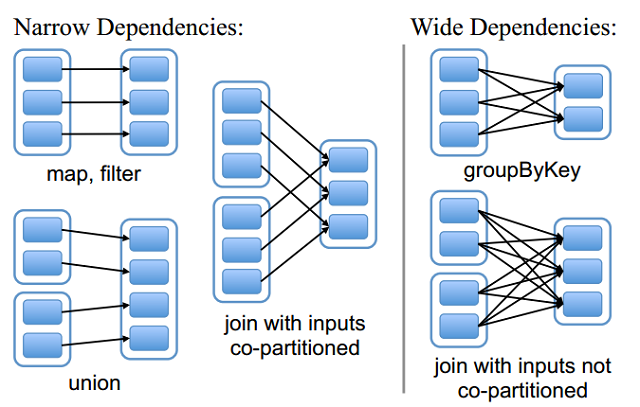
左边图是窄依赖,右边图是宽依赖,窄依赖里面的partition的对应顺序是不变的,款依赖会涉及shuffle操作,会造成partition混洗,因此往往以款依赖划分stage。在上面的操作中,saveAsTextFile是action,reduceByKey是宽依赖,因此这个应用总共有1个job,两个stage,然后在不同的stage中会执行tasks。
源码剖析
从rdd链开始分析。
def textFile(
path: String,
minPartitions: Int = defaultMinPartitions): RDD[String] = withScope {
assertNotStopped()
hadoopFile(path, classOf[TextInputFormat], classOf[LongWritable], classOf[Text],
minPartitions).map(pair => pair._2.toString).setName(path)
}
textFile 这个算子的返回结果是一个RDD,然后RDD链就开始了,可以看出来他调用了一些新的函数,比如hadoopFile啥的,这些我们都不管,因为他们都没有触发 commitJob,所以这些中间过程我们就省略,直到saveAsTextFile这个action。
提交job
def saveAsTextFile(path: String): Unit = withScope {
// https://issues.apache.org/jira/browse/SPARK-2075
//
// NullWritable is a `Comparable` in Hadoop 1.+, so the compiler cannot find an implicit
// Ordering for it and will use the default `null`. However, it's a `Comparable[NullWritable]`
// in Hadoop 2.+, so the compiler will call the implicit `Ordering.ordered` method to create an
// Ordering for `NullWritable`. That's why the compiler will generate different anonymous
// classes for `saveAsTextFile` in Hadoop 1.+ and Hadoop 2.+.
//
// Therefore, here we provide an explicit Ordering `null` to make sure the compiler generate
// same bytecodes for `saveAsTextFile`.
val nullWritableClassTag = implicitly[ClassTag[NullWritable]]
val textClassTag = implicitly[ClassTag[Text]]
val r = this.mapPartitions { iter =>
val text = new Text()
iter.map { x =>
text.set(x.toString)
(NullWritable.get(), text)
}
}
RDD.rddToPairRDDFunctions(r)(nullWritableClassTag, textClassTag, null)
.saveAsHadoopFile[TextOutputFormat[NullWritable, Text]](path)
}
//接下来调用这个
def saveAsHadoopFile[F <: OutputFormat[K, V]](
path: String)(implicit fm: ClassTag[F]): Unit = self.withScope {
saveAsHadoopFile(path, keyClass, valueClass, fm.runtimeClass.asInstanceOf[Class[F]])
}
//省略一部分调用过程
...
...
//最后调用这个函数
def saveAsHadoopDataset(conf: JobConf): Unit = self.withScope {
// Rename this as hadoopConf internally to avoid shadowing (see SPARK-2038).
val hadoopConf = conf
val outputFormatInstance = hadoopConf.getOutputFormat
val keyClass = hadoopConf.getOutputKeyClass
val valueClass = hadoopConf.getOutputValueClass
if (outputFormatInstance == null) {
throw new SparkException("Output format class not set")
}
if (keyClass == null) {
throw new SparkException("Output key class not set")
}
if (valueClass == null) {
throw new SparkException("Output value class not set")
}
SparkHadoopUtil.get.addCredentials(hadoopConf)
logDebug("Saving as hadoop file of type (" + keyClass.getSimpleName + ", " +
valueClass.getSimpleName + ")")
if (isOutputSpecValidationEnabled) {
// FileOutputFormat ignores the filesystem parameter
val ignoredFs = FileSystem.get(hadoopConf)
hadoopConf.getOutputFormat.checkOutputSpecs(ignoredFs, hadoopConf)
}
val writer = new SparkHadoopWriter(hadoopConf)
writer.preSetup()
val writeToFile = (context: TaskContext, iter: Iterator[(K, V)]) => {
// Hadoop wants a 32-bit task attempt ID, so if ours is bigger than Int.MaxValue, roll it
// around by taking a mod. We expect that no task will be attempted 2 billion times.
val taskAttemptId = (context.taskAttemptId % Int.MaxValue).toInt
val outputMetricsAndBytesWrittenCallback: Option[(OutputMetrics, () => Long)] =
initHadoopOutputMetrics(context)
writer.setup(context.stageId, context.partitionId, taskAttemptId)
writer.open()
var recordsWritten = 0L
Utils.tryWithSafeFinallyAndFailureCallbacks {
while (iter.hasNext) {
val record = iter.next()
writer.write(record._1.asInstanceOf[AnyRef], record._2.asInstanceOf[AnyRef])
// Update bytes written metric every few records
maybeUpdateOutputMetrics(outputMetricsAndBytesWrittenCallback, recordsWritten)
recordsWritten += 1
}
}(finallyBlock = writer.close())
writer.commit()
outputMetricsAndBytesWrittenCallback.foreach { case (om, callback) =>
om.setBytesWritten(callback())
om.setRecordsWritten(recordsWritten)
}
}
self.context.runJob(self, writeToFile)
writer.commitJob()
}
上面是saveAstextFile的调用过程,中间省略了一个函数,看代码的最后两行。可以看出调用了 self.context.runJob()可以知道这里触发了job的提交。
def runJob[T, U: ClassTag](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
resultHandler: (Int, U) => Unit): Unit = {
if (stopped.get()) {
throw new IllegalStateException("SparkContext has been shutdown")
}
val callSite = getCallSite
val cleanedFunc = clean(func)
logInfo("Starting job: " + callSite.shortForm)
if (conf.getBoolean("spark.logLineage", false)) {
logInfo("RDD's recursive dependencies:\n" + rdd.toDebugString)
}
dagScheduler.runJob(rdd, cleanedFunc, partitions, callSite, resultHandler, localProperties.get)
progressBar.foreach(_.finishAll())
rdd.doCheckpoint() //是否cache rdd
}
可以看出上面代码有 dagScheduler.runJob,开始进行调度。
def runJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): Unit = {
val start = System.nanoTime
val waiter = submitJob(rdd, func, partitions, callSite, resultHandler, properties)
// Note: Do not call Await.ready(future) because that calls `scala.concurrent.blocking`,
// which causes concurrent SQL executions to fail if a fork-join pool is used. Note that
// due to idiosyncrasies in Scala, `awaitPermission` is not actually used anywhere so it's
// safe to pass in null here. For more detail, see SPARK-13747.
val awaitPermission = null.asInstanceOf[scala.concurrent.CanAwait]
waiter.completionFuture.ready(Duration.Inf)(awaitPermission)
waiter.completionFuture.value.get match {
case scala.util.Success(_) =>
logInfo("Job %d finished: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
case scala.util.Failure(exception) =>
logInfo("Job %d failed: %s, took %f s".format
(waiter.jobId, callSite.shortForm, (System.nanoTime - start) / 1e9))
// SPARK-8644: Include user stack trace in exceptions coming from DAGScheduler.
val callerStackTrace = Thread.currentThread().getStackTrace.tail
exception.setStackTrace(exception.getStackTrace ++ callerStackTrace)
throw exception
}
}
在 dagScheduler.runJob()里面有 submitJob的操作,提交job。
看下面submitJob的代码。
def submitJob[T, U](
rdd: RDD[T],
func: (TaskContext, Iterator[T]) => U,
partitions: Seq[Int],
callSite: CallSite,
resultHandler: (Int, U) => Unit,
properties: Properties): JobWaiter[U] = {
// Check to make sure we are not launching a task on a partition that does not exist.
val maxPartitions = rdd.partitions.length
partitions.find(p => p >= maxPartitions || p < 0).foreach { p =>
throw new IllegalArgumentException(
"Attempting to access a non-existent partition: " + p + ". " +
"Total number of partitions: " + maxPartitions)
}
val jobId = nextJobId.getAndIncrement()
if (partitions.size == 0) {
// Return immediately if the job is running 0 tasks
return new JobWaiter[U](this, jobId, 0, resultHandler)
}
assert(partitions.size > 0)
val func2 = func.asInstanceOf[(TaskContext, Iterator[_]) => _]
val waiter = new JobWaiter(this, jobId, partitions.size, resultHandler)
eventProcessLoop.post(JobSubmitted(
jobId, rdd, func2, partitions.toArray, callSite, waiter,
SerializationUtils.clone(properties)))
waiter
}
然后eventProcessLoop.post(JobSubmitted … 然后就有循环程序处理 这个post。
private def doOnReceive(event: DAGSchedulerEvent): Unit = event match {
case JobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties) =>
dagScheduler.handleJobSubmitted(jobId, rdd, func, partitions, callSite, listener, properties)
划分stage
提交完job之后,会对stage进行划分。
handleJobSubmitted,如下代码。
private[scheduler] def handleJobSubmitted(jobId: Int,
finalRDD: RDD[_],
func: (TaskContext, Iterator[_]) => _,
partitions: Array[Int],
callSite: CallSite,
listener: JobListener,
properties: Properties) {
var finalStage: ResultStage = null
try {
// New stage creation may throw an exception if, for example, jobs are run on a
// HadoopRDD whose underlying HDFS files have been deleted.
finalStage = newResultStage(finalRDD, func, partitions, jobId, callSite)
} catch {
case e: Exception =>
logWarning("Creating new stage failed due to exception - job: " + jobId, e)
listener.jobFailed(e)
return
}
val job = new ActiveJob(jobId, finalStage, callSite, listener, properties)
clearCacheLocs()
logInfo("Got job %s (%s) with %d output partitions".format(
job.jobId, callSite.shortForm, partitions.length))
logInfo("Final stage: " + finalStage + " (" + finalStage.name + ")")
logInfo("Parents of final stage: " + finalStage.parents)
logInfo("Missing parents: " + getMissingParentStages(finalStage))
val jobSubmissionTime = clock.getTimeMillis()
jobIdToActiveJob(jobId) = job
activeJobs += job
finalStage.setActiveJob(job)
val stageIds = jobIdToStageIds(jobId).toArray
val stageInfos = stageIds.flatMap(id => stageIdToStage.get(id).map(_.latestInfo))
listenerBus.post(
SparkListenerJobStart(job.jobId, jobSubmissionTime, stageInfos, properties))
submitStage(finalStage)
submitWaitingStages()
}
解释下这段代码,先是找到最后一个stage, finalStage,然后就生成stageId还有stage的一些信息,然后post 出job开始的消息,然后提交最后一个stage,最后一行是提交等待的stages。
/** Submits stage, but first recursively submits any missing parents. */
private def submitStage(stage: Stage) {
val jobId = activeJobForStage(stage)
if (jobId.isDefined) {
logDebug("submitStage(" + stage + ")")
if (!waitingStages(stage) && !runningStages(stage) && !failedStages(stage)) {
val missing = getMissingParentStages(stage).sortBy(_.id)
logDebug("missing: " + missing)
if (missing.isEmpty) {
logInfo("Submitting " + stage + " (" + stage.rdd + "), which has no missing parents")
submitMissingTasks(stage, jobId.get)
} else {
for (parent <- missing) {
submitStage(parent)
}
waitingStages += stage
}
}
} else {
abortStage(stage, "No active job for stage " + stage.id, None)
}
}
解释下这段代码,就是递归提交之前都没有提交的stage,因为之前是提交最后一个stage吗,但是前面stage也没操作,所以要不断地提交parentStage,直到job的头部。如果说这个stage没有未完成的parentStage,那就代表它前面都执行完毕。
提交tasks###
找到最开始还没完成的stage,那么提交这个stage的Tasks。调用的函数是submitMissingTasks(stage,jobId.get).
下面是 这个函数的代码,有点长。
private def submitMissingTasks(stage: Stage, jobId: Int) {
logDebug("submitMissingTasks(" + stage + ")")
// Get our pending tasks and remember them in our pendingTasks entry
stage.pendingPartitions.clear()
// First figure out the indexes of partition ids to compute.
val partitionsToCompute: Seq[Int] = stage.findMissingPartitions()
// Use the scheduling pool, job group, description, etc. from an ActiveJob associated
// with this Stage
val properties = jobIdToActiveJob(jobId).properties
runningStages += stage
// SparkListenerStageSubmitted should be posted before testing whether tasks are
// serializable. If tasks are not serializable, a SparkListenerStageCompleted event
// will be posted, which should always come after a corresponding SparkListenerStageSubmitted
// event.
stage match {
case s: ShuffleMapStage =>
outputCommitCoordinator.stageStart(stage = s.id, maxPartitionId = s.numPartitions - 1)
case s: ResultStage =>
outputCommitCoordinator.stageStart(
stage = s.id, maxPartitionId = s.rdd.partitions.length - 1)
}
val taskIdToLocations: Map[Int, Seq[TaskLocation]] = try {
stage match {
case s: ShuffleMapStage =>
partitionsToCompute.map { id => (id, getPreferredLocs(stage.rdd, id))}.toMap
case s: ResultStage =>
val job = s.activeJob.get
partitionsToCompute.map { id =>
val p = s.partitions(id)
(id, getPreferredLocs(stage.rdd, p))
}.toMap
}
} catch {
case NonFatal(e) =>
stage.makeNewStageAttempt(partitionsToCompute.size)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)
listenerBus.post(SparkListenerStageSubmitted(stage.latestInfo, properties))
// TODO: Maybe we can keep the taskBinary in Stage to avoid serializing it multiple times.
// Broadcasted binary for the task, used to dispatch tasks to executors. Note that we broadcast
// the serialized copy of the RDD and for each task we will deserialize it, which means each
// task gets a different copy of the RDD. This provides stronger isolation between tasks that
// might modify state of objects referenced in their closures. This is necessary in Hadoop
// where the JobConf/Configuration object is not thread-safe.
var taskBinary: Broadcast[Array[Byte]] = null
try {
// For ShuffleMapTask, serialize and broadcast (rdd, shuffleDep).
// For ResultTask, serialize and broadcast (rdd, func).
val taskBinaryBytes: Array[Byte] = stage match {
case stage: ShuffleMapStage =>
JavaUtils.bufferToArray(
closureSerializer.serialize((stage.rdd, stage.shuffleDep): AnyRef))
case stage: ResultStage =>
JavaUtils.bufferToArray(closureSerializer.serialize((stage.rdd, stage.func): AnyRef))
}
taskBinary = sc.broadcast(taskBinaryBytes)
} catch {
// In the case of a failure during serialization, abort the stage.
case e: NotSerializableException =>
abortStage(stage, "Task not serializable: " + e.toString, Some(e))
runningStages -= stage
// Abort execution
return
case NonFatal(e) =>
abortStage(stage, s"Task serialization failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
val tasks: Seq[Task[_]] = try {
stage match {
case stage: ShuffleMapStage =>
partitionsToCompute.map { id =>
val locs = taskIdToLocations(id)
val part = stage.rdd.partitions(id)
new ShuffleMapTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, stage.latestInfo.taskMetrics, properties)
}
case stage: ResultStage =>
val job = stage.activeJob.get
partitionsToCompute.map { id =>
val p: Int = stage.partitions(id)
val part = stage.rdd.partitions(p)
val locs = taskIdToLocations(id)
new ResultTask(stage.id, stage.latestInfo.attemptId,
taskBinary, part, locs, id, properties, stage.latestInfo.taskMetrics)
}
}
} catch {
case NonFatal(e) =>
abortStage(stage, s"Task creation failed: $e\n${Utils.exceptionString(e)}", Some(e))
runningStages -= stage
return
}
if (tasks.size > 0) {
logInfo("Submitting " + tasks.size + " missing tasks from " + stage + " (" + stage.rdd + ")")
stage.pendingPartitions ++= tasks.map(_.partitionId)
logDebug("New pending partitions: " + stage.pendingPartitions)
taskScheduler.submitTasks(new TaskSet(
tasks.toArray, stage.id, stage.latestInfo.attemptId, jobId, properties))
stage.latestInfo.submissionTime = Some(clock.getTimeMillis())
} else {
// Because we posted SparkListenerStageSubmitted earlier, we should mark
// the stage as completed here in case there are no tasks to run
markStageAsFinished(stage, None)
val debugString = stage match {
case stage: ShuffleMapStage =>
s"Stage ${stage} is actually done; " +
s"(available: ${stage.isAvailable}," +
s"available outputs: ${stage.numAvailableOutputs}," +
s"partitions: ${stage.numPartitions})"
case stage : ResultStage =>
s"Stage ${stage} is actually done; (partitions: ${stage.numPartitions})"
}
logDebug(debugString)
}
}
上面的代码出现了多次ResultStage和ShuffleMapStage,先介绍一下这个stage。
前面我们说过,WordCount只有一个job,然后reduceByKey是shuffle操作,以这个为stage的边界。那么前面的stage就是ShuffleMapStage,后面的stage就是ResultStage.因为前面会有shuffle操作,而后面是整个job的计算结果,所以叫ResultStage.
ResultStage是有一个函数,应用于rdd的一些partition来计算出这个action的结果。但有些action并不是在每个partition都执行的,比如first().
接下来介绍下这个函数的执行流程。
- 首先是计算出
paritionsToCompute,即用于计算的partition,数据。 - 然后就是
outputCommitCoordinator.stageStart,这个类是用来输出到hdfs上的,然后stageStart的两个参数,就是用于发出信息,两个参数分别是stageId和他要用于计算的partition数目。 - 然后就是计算这个stage用于计算的TaskId对应的task所在的location。因为TaskId和partitionId是对应的,所以也就是计算partitionId对应的taskLocation。然后taskLocation是一个host或者是一个(host,executorId)二元组。
stage.makeNewStageAttempt(partitionsToCompute.size, taskIdToLocations.values.toSeq)这里创建新的attempt 就是代表这个stage执行了几次。因为stage可能会失败的。如果失败就要接着执行,这个attempt从0开始。- 然后就是创建广播变量,然后braocast。广播是用于executor来解析tasks。首先要序列化,给每个task都一个完整的rdd,这样可以让task独立性更强,这对于非线程安全是有必要的。对于ShuffleMapTask我们序列化的数据是
(rdd,shuffleDep),对于resultTask,序列化数据为(rdd,func)。 - 然后是创建tasks,当然Tasks分为shuffleMapTask和resultTask,这都是跟stage类型对应的。这里创建tasks,需要用到一个参数
stage.latestInfo.attemptId,这里是前面提到的。 - 创建完tasks就是后面的
taskScheduler.submitTasks(),这样任务就交由taskScheduler调度了。
override def submitTasks(taskSet: TaskSet) {
val tasks = taskSet.tasks
logInfo("Adding task set " + taskSet.id + " with " + tasks.length + " tasks")
this.synchronized {
val manager = createTaskSetManager(taskSet, maxTaskFailures)
val stage = taskSet.stageId
val stageTaskSets =
taskSetsByStageIdAndAttempt.getOrElseUpdate(stage, new HashMap[Int, TaskSetManager])
stageTaskSets(taskSet.stageAttemptId) = manager
val conflictingTaskSet = stageTaskSets.exists { case (_, ts) =>
ts.taskSet != taskSet && !ts.isZombie
}
if (conflictingTaskSet) {
throw new IllegalStateException(s"more than one active taskSet for stage $stage:" +
s" ${stageTaskSets.toSeq.map{_._2.taskSet.id}.mkString(",")}")
}
schedulableBuilder.addTaskSetManager(manager, manager.taskSet.properties)
if (!isLocal && !hasReceivedTask) {
starvationTimer.scheduleAtFixedRate(new TimerTask() {
override def run() {
if (!hasLaunchedTask) {
logWarning("Initial job has not accepted any resources; " +
"check your cluster UI to ensure that workers are registered " +
"and have sufficient resources")
} else {
this.cancel()
}
}
}, STARVATION_TIMEOUT_MS, STARVATION_TIMEOUT_MS)
}
hasReceivedTask = true
}
backend.reviveOffers()
}
这段代码前面部分就是先创建taskManager,然后判断是否有超过一个数目的tasks存在,如果冲突就报异常。
然后把这个TaskSetManager加入schedulableBuilder,这个变量在初始化时候会选择调度策略,比如fifo啥的,加入之后就会按照相应的策略进行调度。
然后之后的判断是否为本地,和是否已经接收过任务,isLocal代表本地模式。如果非本地模式,而且还没接收到过任务,就会建立一个TimerTask,然后一直查看有没有接收到任务,因为如果没任务就是空转吗。
最后backend就会让这个tasks唤醒。backend.reviveOffers(),这里我们的backend通常是CoarseGrainedSchedulerBackend,在执行reviveOffers之后,driverEndpoint会send消息,然后backend的receive函数会接收到消息,然后执行操作。看CoarseGrainedSchedulerBackend 的receive函数。
override def receive: PartialFunction[Any, Unit] = {
...
case ReviveOffers =>
makeOffers()
...
}
private def makeOffers() {
// Filter out executors under killing
val activeExecutors = executorDataMap.filterKeys(executorIsAlive)
val workOffers = activeExecutors.map { case (id, executorData) =>
new WorkerOffer(id, executorData.executorHost, executorData.freeCores)
}.toSeq
launchTasks(scheduler.resourceOffers(workOffers))
}
上面代码显示筛选出存活的Executors,然后就创建出workerOffers,参数是executorId,host,frescoers.
执行task###
然后就launchTasks。
private def launchTasks(tasks: Seq[Seq[TaskDescription]]) {
for (task <- tasks.flatten) {
val serializedTask = ser.serialize(task)
if (serializedTask.limit >= maxRpcMessageSize) {
scheduler.taskIdToTaskSetManager.get(task.taskId).foreach { taskSetMgr =>
try {
var msg = "Serialized task %s:%d was %d bytes, which exceeds max allowed: " +
"spark.rpc.message.maxSize (%d bytes). Consider increasing " +
"spark.rpc.message.maxSize or using broadcast variables for large values."
msg = msg.format(task.taskId, task.index, serializedTask.limit, maxRpcMessageSize)
taskSetMgr.abort(msg)
} catch {
case e: Exception => logError("Exception in error callback", e)
}
}
}
else {
val executorData = executorDataMap(task.executorId)
executorData.freeCores -= scheduler.CPUS_PER_TASK
logInfo(s"Launching task ${task.taskId} on executor id: ${task.executorId} hostname: " +
s"${executorData.executorHost}.")
executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask)))
}
}
}
上面的代码显示将task序列化,然后根据task.executorId 给他分配executor,然后就executorData.executorEndpoint.send(LaunchTask(new SerializableBuffer(serializedTask))).
这里有一个executorEndPoint,之前前面有driverEndPoint(出现在backend.reviveOffer那里),这两个端口的基类都是RpcEndpointRef。RpcEndpointRef是RpcEndPoint的远程引用,是线程安全的。
RpcEndpoint是 RPC[Remote Procedure Call :远程过程调用]中定义了收到的消息将触发哪个方法。
同时清楚的阐述了生命周期,构造-> onStart -> receive* -> onStop
这里receive* 是指receive 和 receiveAndReply。
他们的区别是:
receive是无需等待答复,而receiveAndReply是会阻塞线程,直至有答复的。(参考:http://www.07net01.com/2016/04/1434116.html)
然后这里的driverEndPoint就是代表这个信息会发给CoarseGrainedSchedulerBackEnd,executorEndPoint就是发给coarseGrainedExecutorBackEnd当然就是发给coarseGrainedExecutorBackEnd。接下来去看相应的recieve代码。
override def receive: PartialFunction[Any, Unit] = {
...
case LaunchTask(data) =>
if (executor == null) {
exitExecutor(1, "Received LaunchTask command but executor was null")
} else {
val taskDesc = ser.deserialize[TaskDescription](data.value)
logInfo("Got assigned task " + taskDesc.taskId)
executor.launchTask(this, taskId = taskDesc.taskId, attemptNumber = taskDesc.attemptNumber,
taskDesc.name, taskDesc.serializedTask)
}
...
}
这里先将传过来的数据反序列化,然后executor.launchTask.
def launchTask(
context: ExecutorBackend,
taskId: Long,
attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer): Unit = {
val tr = new TaskRunner(context, taskId = taskId, attemptNumber = attemptNumber, taskName,
serializedTask)
runningTasks.put(taskId, tr)
threadPool.execute(tr)
}
这里新建了taskRunner,然后之后交由线程池来运行,线程池既然要运行taskRunner,必定是运行taskRunner的run方法。看taskRunner的run方法,代码太长,懒得贴,大概描述下。
主要就是设置参数,属性,反序列化出task等等,之后就要调用task.runTask方法。这里的task可能是ShuffleMapTask也可能是ResultTask,所以我们分别看这两种task的run方法。
ShuffleMapTask
先看ShuffleMapTask。
override def runTask(context: TaskContext): MapStatus = {
// Deserialize the RDD using the broadcast variable.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, dep) = ser.deserialize[(RDD[_], ShuffleDependency[_, _, _])](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
var writer: ShuffleWriter[Any, Any] = null
try {
val manager = SparkEnv.get.shuffleManager
writer = manager.getWriter[Any, Any](dep.shuffleHandle, partitionId, context)
writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]])
writer.stop(success = true).get
} catch {
case e: Exception =>
try {
if (writer != null) {
writer.stop(success = false)
}
} catch {
case e: Exception =>
log.debug("Could not stop writer", e)
}
throw e
}
}
前面部分代码就是反序列化那些,主要看中间的代码。获得shuffleManager,然后getWriter。因为shuffleMapTask有Shuffle操作,所以要shuffleWrite。
ResultTask####
看下ResultTask的runTask。
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
func(context, rdd.iterator(partition, context))
}
跟那个差不多,只不过不是shuffleWrite,是func.
rdd 迭代链
看这行代码writer.write(rdd.iterator(partition, context).asInstanceOf[Iterator[_ <: Product2[Any, Any]]]),看write方法里面的参数,rdd.iterator方法。
final def iterator(split: Partition, context: TaskContext): Iterator[T] = {
if (storageLevel != StorageLevel.NONE) {
getOrCompute(split, context)
} else {
computeOrReadCheckpoint(split, context)
}
}
这个方法,是从后面的rdd开始迭代,首先判断这个rdd是否是已经被cache。
如果已经被cache,getOrCompute,直接get,或者如果没找到就重算一遍,这个代码比较简单,我就不贴了。
如果没有被cache,则调用computeOrReadCheckpoint。
private[spark] def computeOrReadCheckpoint(split: Partition, context: TaskContext): Iterator[T] =
{
if (isCheckpointedAndMaterialized) {
firstParent[T].iterator(split, context)
} else {
compute(split, context)
}
}
如果是检查点,先介绍下检查点。
检查点####
检查点机制的实现和持久化的实现有着较大的区别。检查点并非第一次计算就将结果进行存储,而是等到一个作业结束后启动专门的一个作业完成存储的操作。
checkPoint操作的实现在RDD类中,checkPoint方法会实例化ReliableRDDCheckpointData用于标记当前的RDD
/**
* Mark this RDD for checkpointing. It will be saved to a file inside the checkpoint
* directory set with `SparkContext#setCheckpointDir` and all references to its parent
* RDDs will be removed. This function must be called before any job has been
* executed on this RDD. It is strongly recommended that this RDD is persisted in
* memory, otherwise saving it on a file will require recomputation.
*/
def checkpoint(): Unit = RDDCheckpointData.synchronized {
// NOTE: we use a global lock here due to complexities downstream with ensuring
// children RDD partitions point to the correct parent partitions. In the future
// we should revisit this consideration.
if (context.checkpointDir.isEmpty) {
throw new SparkException("Checkpoint directory has not been set in the SparkContext")
} else if (checkpointData.isEmpty) {
checkpointData = Some(new ReliableRDDCheckpointData(this))
}
}
RDDCheckpointData类内部有一个枚举类型 CheckpointState
/**
* Enumeration to manage state transitions of an RDD through checkpointing
* [ Initialized --> checkpointing in progress --> checkpointed ].
*/
private[spark] object CheckpointState extends Enumeration {
type CheckpointState = Value
val Initialized, CheckpointingInProgress, Checkpointed = Value
}
用于表示RDD检查点的当前状态,其值有Initialized 、CheckpointingInProgress、 checkpointed。其转换过程如下 (1)Initialized状态
该状态是实例化ReliableRDDCheckpointData后的默认状态,用于标记当前的RDD已经建立了检查点(较v1.4.x少一个MarkForCheckPiont状态)
(2)CheckpointingInProgress状态
每个作业结束后都会对作业的末RDD调用其doCheckPoint方法,该方法会顺着RDD的关系依赖链往前遍历,直到遇见内部RDDCheckpointData对象被标记为Initialized的为止,此时将RDD的RDDCheckpointData对象标记为CheckpointingInProgress,并启动一个作业完成数据的写入操作。
(3)Checkpointed状态
新启动作业完成数据写入操作之后,将建立检查点的RDD的所有依赖全部清除,将RDD内部的RDDCheckpointData对象标记为Checkpointed,将父RDD重新设置为一个CheckPointRDD对象,父RDD的compute方法会直接从系统中读取数据。
如上只简单地介绍了相关概念,详细介绍请参看:https://github.com/JerryLead/SparkInternals/blob/master/markdown/6-CacheAndCheckpoint.md
compute 链
上面有检查点的就直接去父Rdd的compute读取数据了。而非检查点,就compute,compute是一个链。
拿MapPartitionsRDD举个例子,看看它的compute方法。
override def compute(split: Partition, context: TaskContext): Iterator[U] =
f(context, split.index, firstParent[T].iterator(split, context))
看这里 compute还是调用了iterator,所以还是接着往前找了,直到找到checkpoint或者就是到rdd头。
再看看其他的rdd的compute方法吧。
看看ShuffleRdd.
override def compute(split: Partition, context: TaskContext): Iterator[(K, C)] = {
val dep = dependencies.head.asInstanceOf[ShuffleDependency[K, V, C]]
SparkEnv.get.shuffleManager.getReader(dep.shuffleHandle, split.index, split.index + 1, context)
.read()
.asInstanceOf[Iterator[(K, C)]]
}
然后这里shuffleRdd的compute方法就是从shuffle 那里read 数据,这算是一个stage的开始了。
当然一个stage的开始未必是shuffleRead开始啦,比如textFile,它最终是返回一个HadoopRdd,然后他的compute方法,就是返回一个迭代器。